Scraping websites with Temporal
A simple website scraper using temporal.io and where to go from there.
The repository can be found at: github.com/aurelien-clu/temporal-scraper
TLDR
The project fetches a web page, extracts the title and links and finally saves it on disk in a JSON file.
Pre-requisites
- Install
python 3.9or pyenv - Install poetry
- Install temporal CLI
Setup
git clone https://github.com/aurelien-clu/temporal-scraper <your-project>
cd <your-project>
# skip if python 3.9 is already installed with or without pyenv
pyenv install 3.9.10
# update path to your own python 3.9 installation
poetry env use ~/.pyenv/versions/3.9.10/bin/python3.9
# install packages
poetry install
Run
# terminal 1
temporal server start-dev
# terminal 2, within your python environment
python src/run_worker.py
# you could start more workers with more terminals, here it won't be necessary
# terminal 3, within your python environment
mkdir -p data
python src/run_workflow.py --url=https://news.yahoo.com --output-dir=data
And then in data/ you should find:
{
"url": "https://news.yahoo.com/",
"title": "Yahoo News - Latest News & Headlines",
"links": [
"https://www.yahoo.com/",
"https://mail.yahoo.com/",
"https://news.yahoo.com/",
"https://finance.yahoo.com/",
"https://sports.yahoo.com/",
"[...]"
]
}
Go to 127.0.0.1:8233/namespaces/default/workflows to see the temporal web UI.
You can see your recent workflow executions:

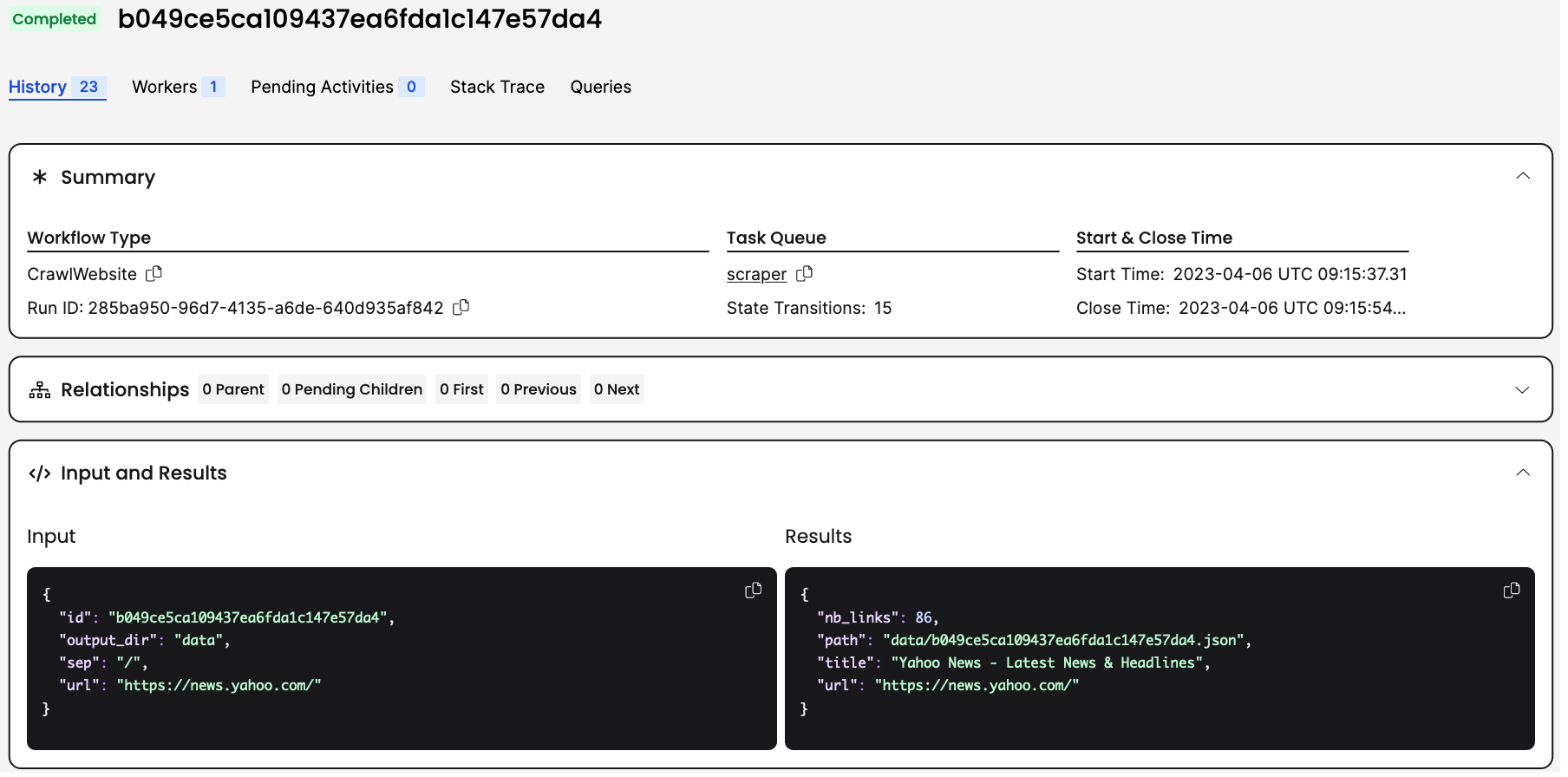
When selected, you have a top summary:
And finally you can see all events related to the workflow execution:
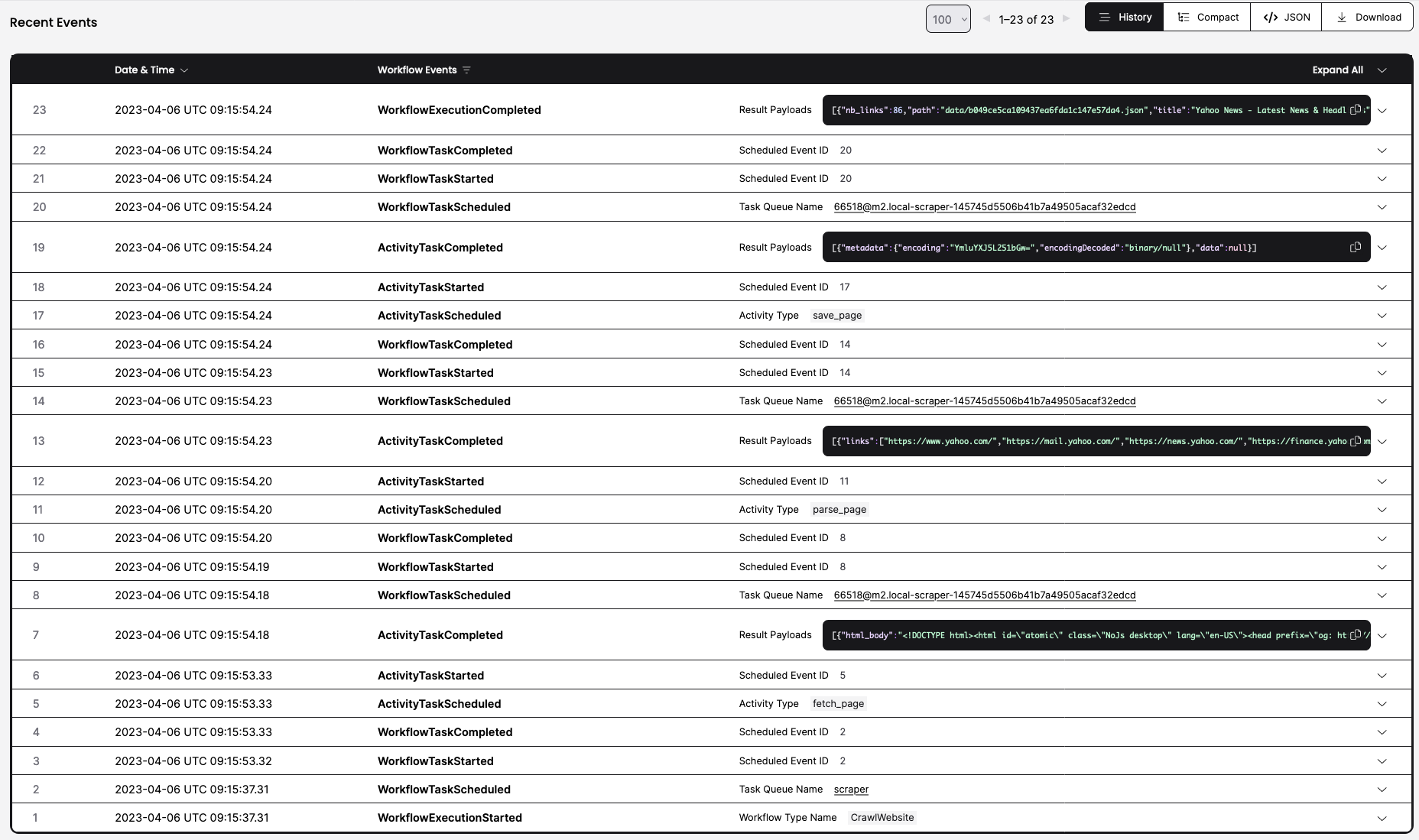
this includes inputs, outputs, retries, exceptions, etc.
Implementation walkthrough
Workflow
Our workflow goes like this:
- fetch the web page at the input URL
- parse de page and extract the information we are interested in: the title & links
- save on disk
- return a result containing the title, links and the path to the saved file
To make it a temporalio workflow, we simply need to decorate the class: @workflow.defn and the run method: @workflow.run.
@workflow.defn
class CrawlWebsite:
@workflow.run
async def run(self, cmd: CrawlUrl) -> Output:
# STEP 1: fetch
page: FetchedPage = await workflow.execute_activity(
fetch_page,
cmd.url,
schedule_to_close_timeout=timedelta(seconds=5),
)
# STEP 2: parse
parsed: ParsedPage = await workflow.execute_activity(
parse_page,
page,
schedule_to_close_timeout=timedelta(seconds=5),
)
# STEP 3: save
path = cmd.output_dir + cmd.sep + f"{cmd.id}.json"
to_save = SavePage(path=path, page=parsed)
await workflow.execute_activity(
save_page,
to_save,
schedule_to_close_timeout=timedelta(seconds=5),
)
# STEP 4: return
return Output(
url=cmd.url,
title=parsed.title,
nb_links=len(parsed.links),
path=to_save.path,
)
For our workflow to work, we need to:
- define the model, i.e.
- input:
CrawlUrl - intermediary results:
ParsedPage,SavePage - final result:
Output
- input:
- implement
activitiesi.e. each workflow stepsfetch_pageparse_pagesave_page
Model
The model is pure python dataclass which facilitates a lot the implementation.
@dataclass
class CrawlUrl:
id: str
url: str
# temporal.io forces workflow to be as deterministic as possible (and it is a good thing)
# => os is not available during the workflow => necessary to provide it as an input
# as I did not want to call it during an activity, though it could have been done this way
sep: str
output_dir: str
@dataclass
class FetchedPage:
url: str
html_body: str
@dataclass
class ParsedPage:
url: str
title: str
links: t.List[str]
@dataclass
class SavePage:
path: str
# you could also want to save the raw html body
page: ParsedPage
@dataclass
class Output:
url: str
title: str
nb_links: int
path: str
Activities
Now that we have the workflow and the model, we need to implement each step.
Each step is an async function with the appropriate decoration @activity.defn.
@activity.defn
async def fetch_page(url: str) -> FetchedPage:
# using httpx because it is a nice http library
# with sync & async methods
async with httpx.AsyncClient() as client:
response = await client.get(url)
response.raise_for_status()
content_str = response.text
return FetchedPage(url=url, html_body=content_str)
@activity.defn
async def parse_page(page: FetchedPage) -> ParsedPage:
def extract_title(soup):
for title in soup.find_all("title"):
return title.get_text()
return ""
def extract_links(soup, url_parsed):
for node in soup.find_all("a"):
link = node.get("href")
# prefix relative links with the input url domain
if link.startswith("/"):
link = url_parsed.netloc + link
yield link
url_parsed = urlparse(page.url)
soup = bs4.BeautifulSoup(page.html_body, features="html.parser") # parses the HTML
title = extract_title(soup)
links = list(extract_links(soup, url_parsed))
return ParsedPage(url=page.url, title=title, links=links)
@activity.defn
async def save_page(to_save: SavePage):
with open(to_save.path, "w") as f:
# in Python, objects are underneath simple dict,
# accessible at .__dict__
# for our simple example this works well,
# beware for more complex classes
json.dump(to_save.page.__dict__, f, indent=4)
Run
Now that we have our workflow with its steps, we need to be able to start it.
For that we need:
- a worker to be able to execute the workflow and the activities
- a way to tell at
temporalio, "start my workflow"
Note:
You could have specialized workers, some running workflows, other certain activities and other running other activities. (e.g. you could have activities needing specialized hardware such as GPUs to run AI models)
The following assigns the worker, workflows and activities it can execute.
# [...]
from activities import *
from workflows import *
async def async_start_worker(temporal_server: str, task_queue: str):
client = await Client.connect(temporal_server)
worker = Worker(
client,
task_queue=task_queue,
workflows=[CrawlWebsite],
activities=[fetch_page, parse_page, save_page],
)
await worker.run()
# this wraps our async function to execute outside of an async context
def start_worker(
temporal_server: str = "localhost:7233",
task_queue="scraper",
):
future = async_start_worker(
temporal_server=temporal_server,
task_queue=task_queue,
)
return asyncio.run(future)
# https://github.com/google/python-fire to create python CLI with no efforts
if __name__ == "__main__":
fire.Fire(start_worker)
this starts a workflow with its required CrawlUrl input.
# [...]
from model import CrawlUrl
from workflows import CrawlWebsite
async def async_crawl(
url: str,
output_dir: str,
temporal_server: str,
task_queue: str,
):
crawl_cmd = CrawlUrl(
id=uuid.uuid4().hex,
url=url,
sep=os.sep,
output_dir=output_dir,
)
client = await Client.connect(temporal_server)
logger.info(f"starting: {crawl_cmd}...")
result = await client.execute_workflow(
CrawlWebsite.run,
crawl_cmd,
id=crawl_cmd.id,
task_queue=task_queue,
)
logger.success(f"{result}")
# and then we wrap the async function just like in the `src/run_worker.py`
# and generate the CLI with python-fire
# [...]
Going further
This example is pretty simple whereas temporalio can be quite complex.
We could improve it with:
- start children workflows for each link found within the domain (or for all links)
- verify the domain robots.txt to cancel scraping if forbidden
- don't start or cancel children workflows on already scraped links
- parse additional content in web page
- store raw html body as well
- control workflow execution with signals to pause, resume or stop
- ensure scraping fairness per domain (not flooding but scraping at a certain pace to prevent any impact - limiting the number of workers may at first be sufficient)
- [...]